How LLMs Are Built
Veliki jezički modeli (LLM-ovi) su AI sistemi koji mogu da razumeju i generišu tekst. Uprkos njihovim naizgled magičnim sposobnostima, ovi modeli ne razmišljaju, ne rezonuju i ne razumeju kao ljudi. To su sofisticirani sistemi za prepoznavanje obrazaca koji su naučili statističku strukturu ljudskog jezika obrađujući milijarde primera.
LLM je jezički model treniran self-supervised mašinskim učenjem na ogromnim količinama teksta, dizajniran za zadatke obrade prirodnog jezika — posebno za generisanje teksta. Najveći i najsposobniji LLM-ovi su generative pre-trained transformer-i (GPT-ovi), i oni čine osnovu modernih chatbot-ova.
What is an LLM
U srži, jezički model je matematički sistem koji je naučio kako jezik "funkcioniše" i može da predvidi ili generiše tekst koji ima smisla. Zamislite to kao autocomplete na velikoj skali — vaš telefon predviđa narednih 1–2 reči, dok LLM predviđa cele pasuse, odgovara na pitanja, piše kod i prevodi između jezika.

| Provajder | Model | Sajt |
|---|---|---|
| OpenAI | ChatGPT | chatgpt.com |
| Anthropic | Claude | claude.ai |
| Gemini | gemini.google.com | |
| xAI | Grok | grok.com |
| Meta | Meta AI | meta.ai |
Self-supervised learning
"Self-supervised" znači da model sam sebi kreira zadatke za učenje iz podataka, bez potrebe da ljudi ručno označavaju ("labeluju") bilo šta. Model čita milione tekstova i sam sebe testira: ako sakrijemo poslednju reč u rečenici, može li da predvidi koja je?
# Conceptual example of self-supervised training
input_text = "I love machine ____"
# Model predicts probabilities:
# "learning" → 75%
# "guns" → 2%
# "banana" → 0.001%
# Original text says "learning"
# ✓ Correct — model improves slightlyModel ponavlja ovaj proces milijarde puta kroz milijarde dokumenata sve dok ne razvije duboko statističko razumevanje jezika.
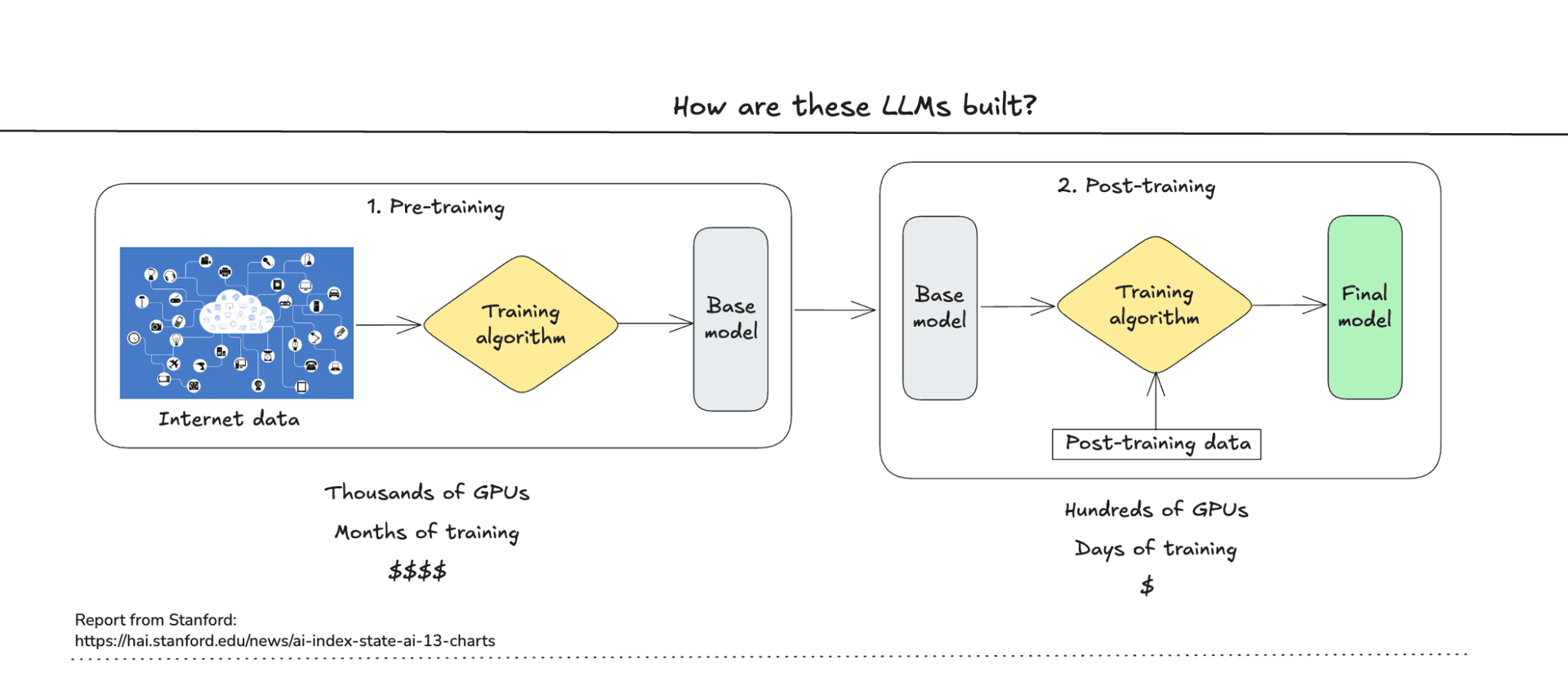
Pre-training and post-training
Izgradnja LLM-a uvek prolazi kroz dve faze: pre-training i post-training.
| Pre-training | Post-training | |
|---|---|---|
| Ulaz | Internet podaci na velikoj skali | Pažljivo izabrani instruction/feedback podaci |
| Izlaz | Base model | Finalni model (ChatGPT, Claude, itd.) |
| GPU-ovi | Hiljade | Stotine |
| Trajanje | Meseci | Dani |
| Cena | $$$$$ | $ |
Pre-training je tu gde se odvija glavni posao. Model se trenira na internet podacima, obrađujući milijarde tokena na hiljadama GPU-ova mesecima. Rezultat je base model sa snažnim razumevanjem jezika, ali bez sposobnosti razgovora.
Post-training pretvara base model u asistenta sa kojim komunicirate. Kroz tehnike kao što su instruction tuning i reinforcement learning from human feedback (RLHF), model uči da prati instrukcije, odbije štetne zahteve i daje korisne odgovore. Ova faza je kraća, jeftinija i zahteva mnogo manje resursa.
Data collection
Prvi korak pre-training-a je prikupljanje teksta sa interneta. Web crawling je automatizovani proces u kojem programi sistematski posećuju veb stranice, preuzimaju njihov sadržaj i prate linkove kako bi otkrili još stranica.
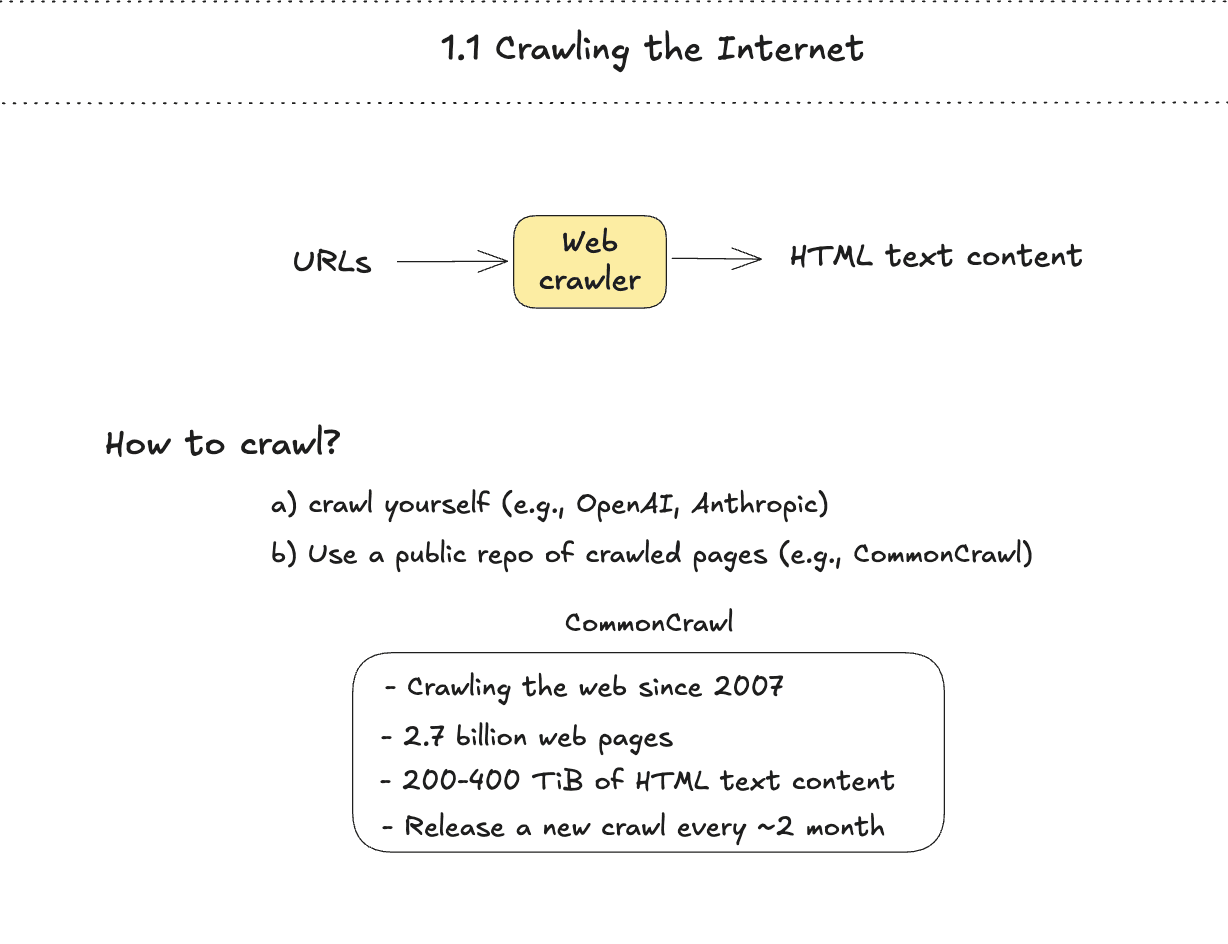
Postoje dva pristupa prikupljanju podataka:
- Crawl-ujte sami — kompanije kao OpenAI i Anthropic imaju sopstvenu crawling infrastrukturu
- Koristite javne dataset-e — koristite podatke koje su drugi već crawl-ovali i objavili
Najpoznatiji javni izvor je CommonCrawl, neprofitna organizacija koja crawl-uje web od 2007. Održava arhivu od približno 2,7 milijardi veb stranica (200–400 TB HTML tekstualnog sadržaja) i objavljuje novi crawl otprilike svaka dva meseca.
Data cleaning
Sirovi web podaci su bučni. Sadrže duplikate, sadržaj niskog kvaliteta, toksičan materijal i lične podatke. Čišćenje je kritično jer je mnogo teže naterati model da nešto zaboravi nego da ga naučite nečemu novom.
"We prioritized filtering out all bad data rather than retaining all good data... we can always fine-tune our model with more data later, but it is much harder to make a model forget something it has already learned." — OpenAI
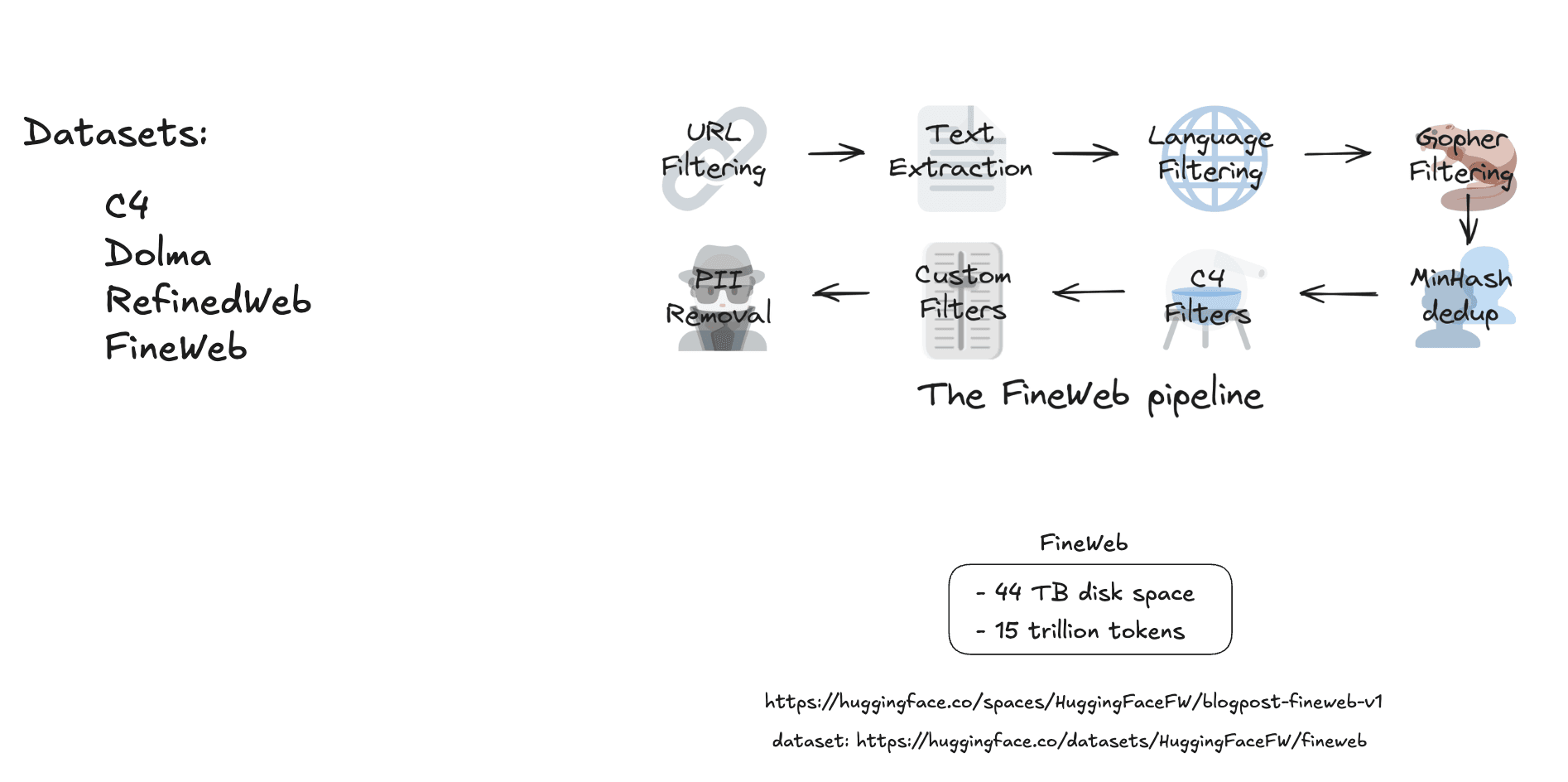
Cleaning pipeline obično uključuje sledeće faze:
| Faza | Svrha | Metoda |
|---|---|---|
| Deduplication | Uklanjanje duplikata / redundantnog teksta | MinHash, exact matching |
| Quality filtering | Uklanjanje sadržaja niskog kvaliteta | Heuristike + klasifikatori |
| Toxicity filtering | Uklanjanje govora mržnje, nasilja, dezinformacija, NSFW, spam-a | Content klasifikatori |
| PII redaction | Anonimizacija ličnih podataka | Pattern matching, NER |
| Tekstualna normalizacija | Standardizacija formata | Pravila / transformacije |
Deduplication je posebno bitan. Isti članak, definicija ili code snippet može da se pojavi na desetinama sajtova. Ako model vidi isti tekst iznova i iznova, naučiće da pamti umesto da generalizuje. To može izazvati "double descent" fenomen i degradirati sposobnost modela da kopira iz konteksta.
Neki izvori zahtevaju i strukturne odluke, ne samo filtriranje. Reddit je, na primer, stablo postova i komentara — morate da odlučite kako da spljoštite to stablo komentara tako da model nauči logičan tok diskusije, i da filtrirate NSFW subreddit-e. Reddit podaci su dovoljno vredni da je pristup njima postao sporan: u junu 2025, Reddit je tužio Anthropic za navodno scraping-ovanje sadržaja radi treniranja Claude-a, što Anthropic osporava.
Nekoliko organizacija objavljuje očišćene dataset-e spremne za treniranje:
| Dataset | Izvor | Veličina |
|---|---|---|
| C4 | 750 GB | |
| Dolma | AI2 | 3 TB |
| RefinedWeb | Falcon/TII | 5 TB |
| FineWeb | HuggingFace | 44 TB (15T tokena) |
Većina LLM-ova koristi C4 kao polaznu tačku. FineWeb je najnoviji, objavljen od strane HuggingFace-a kao potpuno open-source dataset.
From text to numbers
LLM-ovi ne primaju tekst kao ulaz — trebaju im brojevi. Tokenization pretvara sirovi tekst u sekvencu diskretnih brojeva koje model može da obradi.
Token nije isto što i reč. U zavisnosti od tokenizer-a, token može predstavljati pojedinačni karakter, subword (deo reči), kompletnu reč, znak interpunkcije ili whitespace. LLM-ovi obično koriste rečnike (vocabulary) veličine 30.000–100.000 tokena. Razbijanjem retkih ili složenih reči na subword delove (npr. "extraordinary" → "extra" + "ordinary"), ograničen rečnik može da izrazi neograničen jezik.
Kompletan pipeline od teksta do ulaza u model:
Text: "Hello world"
↓ Tokenization
Tokens: ["Hello", " world"]
↓ Token IDs
IDs: [15496, 995]
↓ Embedding layer
Vectors: [[0.23, -0.45, 0.78, ...], [0.12, 0.89, -0.34, ...]]
↓ Transformer
Neural network processes the numerical vectorsSvaka kompanija koristi sopstveni algoritam za tokenization. Efikasnost ovih algoritama direktno utiče na context kapacitet modela i kvalitet izlaza.
Najčešći subword algoritam je Byte-Pair Encoding (BPE), koji iterativno spaja najčešće parove susednih tokena dok rečnik ne dostigne ciljanu veličinu.
Context window
LLM-ovi imaju ograničen context window — maksimalan broj tokena koje mogu da obrade odjednom. Ovaj limit utiče na:
- Dužinu ulaza — koliko teksta model može da uzme u obzir pre nego što generiše odgovor
- Dužinu izlaza — koliko može da generiše u jednoj kompletaciji
- Koherenciju — koliko dobro održava konzistentnost kroz duže razgovore ili dokumente
U praksi, kvalitet modela degradira znatno pre navedenog context limita — vidite Tackling Big Tasks za rad unutar "smart zone" prozora.
Tokenization edge cases
Tokenization može da proizvede neočekivano ponašanje u praksi:
- Non-English languages — tokenizer-i su uglavnom trenirani na engleskom tekstu, pa reči na drugim jezicima često zahtevaju više tokena. Engleska reč "unhappiness" može da se tokenizuje u 2 tokena, dok njen ekvivalent na drugom jeziku može da zahteva 5+
- Special characters — emoji i neobično formatiranje mogu da potroše više tokena nego što se očekuje
- Numbers and code — neki tokenizer-i fragmentiraju brojeve i programske konstrukcije na kontraintuitivne načine, otežavajući aritmetiku i generisanje koda
Further reading
- Deep Dive into LLMs like ChatGPT — Karpathy-jev end-to-end video o izgradnji i treniranju LLM-a; mapira se skoro 1:1 na ovaj pipeline.
- Hugging Face LLM Course — besplatan kurs čija kasnija poglavlja praktično obrađuju dataset-e, tokenizer-e i fine-tuning.
- Tiktokenizer — interaktivni playground za korak "From text to numbers": gledajte kako se tekst deli u tokene i ID-eve po modelu.
Sledeće: Tokenization — dublji pogled na to kako tekst postaje tokeni, zašto je to bitno i gde se lomi.
Izmeni stranicu na GitHub-u