Tackling Big Tasks
A long-running theme in AI-assisted engineering is that size kills. An LLM can finish a small, focused change in seconds, but the same model on a multi-day epic will quietly produce drift, slop, and dead-end code. The fix isn't a smarter model — it's a smaller unit of work.
This article covers three ideas that, together, make big tasks shippable: the smart zone of the context window, the PRD-and-plan split, and tracer bullets for vertical slicing.
The smart zone of the context window
Modern frontier models advertise enormous context windows — 200K, 1M, even more tokens. In practice, a model's effective reasoning quality degrades well before the stated limit. A common community heuristic is that a model stays in its "smart zone" for roughly the first 60–80% of a 200K window — call it ~120K–160K tokens — and starts making subtle mistakes beyond that.
That's a rule of thumb, not a measurement. But the underlying effect is real and well-documented. Chroma's 2025 "context rot" research tested 18 frontier models and found accuracy drops of 30%+ in mid-window positions across every one of them. HumanLayer reported the same: even inside the smart zone of a 200K model, plans were less precise, instructions were ignored, and trivial mistakes appeared as context filled up.
Practical takeaway. Treat the context window as a budget for quality, not just length. Long context isn't free — every additional token dilutes attention to the ones you care about most.
This is why a big feature can't just be dropped into a single prompt. Even when it fits, the model gets worse at it the deeper it goes.
PRD as destination, plan as journey
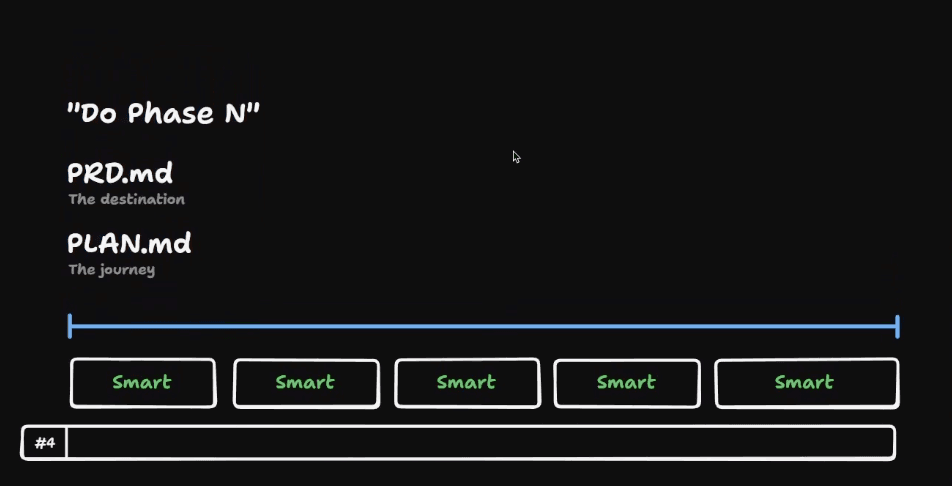
The solution is the same one developers have used for decades: break the work down. Two artifacts do this cleanly:
| Artifact | Role | What it contains |
|---|---|---|
| PRD (Product Requirement Document) | The destination | Precise specification of what you're building — features, user stories, acceptance criteria. No file paths, no function names, no implementation detail. |
| Plan | The journey | The route from "empty repo" to "PRD satisfied," broken into chunks each small enough to live inside a single smart-zone context window. |
The PRD is the same artifact a product manager would historically hand to a developer. In this workflow, the "developer" is the LLM, and the PRD is how you explain to it what to build. User stories are particularly high-leverage — every "As a role, I want capability, so that outcome" line gives the model a why, which it can keep referring back to when it has to make implementation calls later.
Matt Pocock's to-prd skill is a useful starting point: it turns a loose conversation into a structured PRD with user stories.
The trap: implementing layer by layer
When you hand a plan to an LLM and tell it to "build the feature," its natural reflex is to go horizontally: finish the entire backend, then the entire frontend, then QA. Across microservices it does the same — finish service A, then service B.

This feels orderly but creates a real problem: you get no feedback until the very last phase. By the time you find out the contract between backend and frontend was wrong, three layers of work are already built on top of it. The early phases — where mistakes are cheapest to fix — are the ones with no signal.
The plan in this shape is also too specific too early. It references functions and variables that don't exist yet, so the moment an implementation detail shifts, the plan has to be rewritten. It's a plan for vibe coding, not for shipping.
Tracer bullets and vertical slices
The fix is a concept from The Pragmatic Programmer that's been around for decades: tracer bullets. (aihero.dev)
Instead of finishing a horizontal layer at a time, every phase of the plan cuts a vertical slice through every layer of the system — a minimal end-to-end path that actually works. The first phase is small and ugly, but it touches backend, frontend, and tests. You get early feedback that the critical path holds together. Each subsequent phase widens the slice.
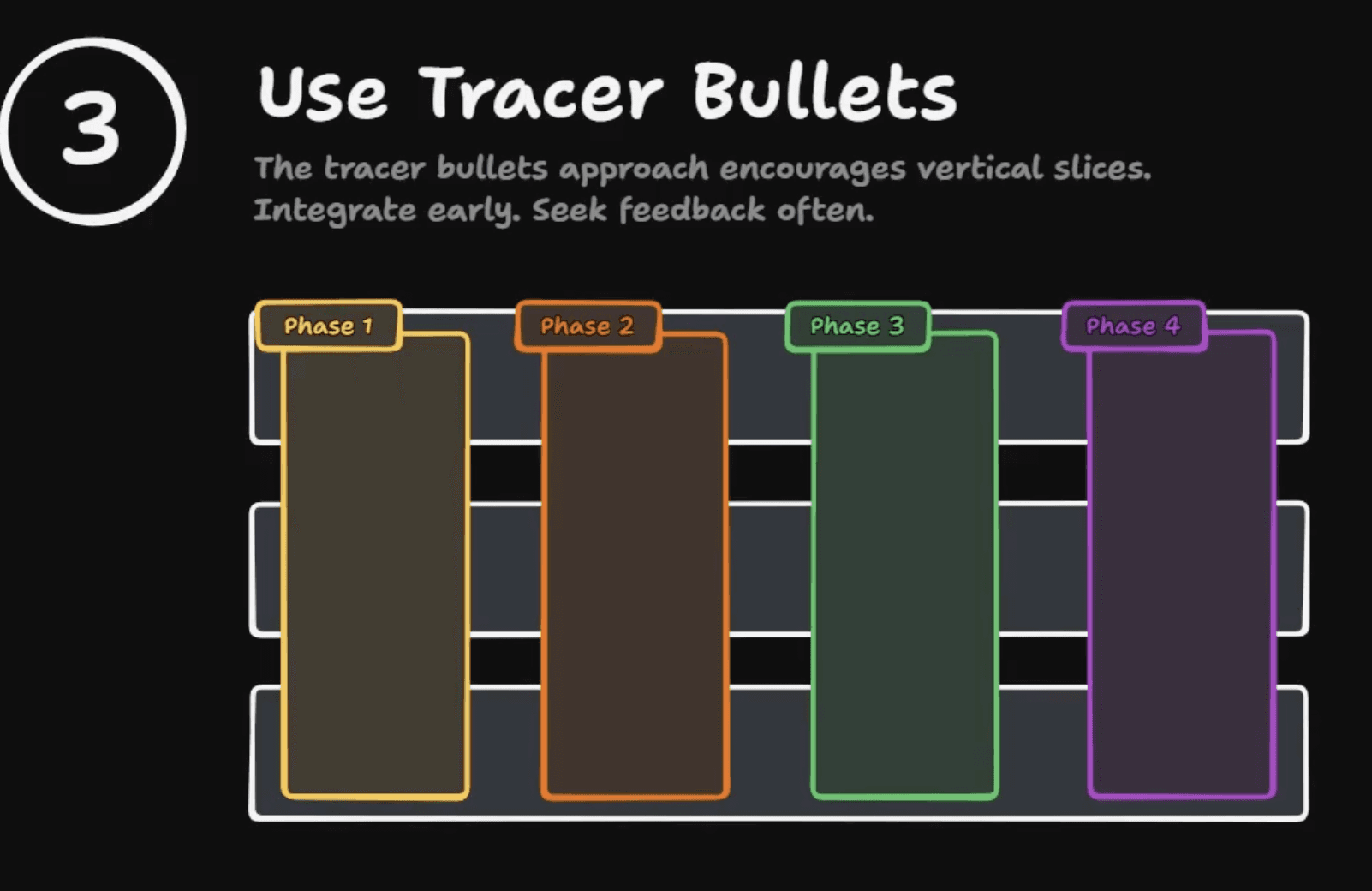
The mantra is: integrate early, seek feedback often. Each vertical slice is a tiny MVP for the task. You verify the contract end-to-end before widening it.
"AI's natural inclination is to build big layers in isolation. You need to make it do an end-to-end slice across all the vertical layers."
Matt Pocock's prd-to-issues skill operationalizes this: it takes a PRD and emits a plan whose phases are vertical slices, each small enough to fit a smart-zone context window. Whether the slices live as phases in a single plan or as separate issues doesn't matter — what matters is that each one is a thin, end-to-end cut.
How this fits together
- Write the PRD — what you're building, why, and for whom. No code-level detail.
- Generate a plan of vertical slices — each one an end-to-end tracer bullet.
- Execute one slice at a time in its own fresh context window, well inside the smart zone.
- After each slice, review the feedback — tests, types, behavior — and adjust the next slice.
The human role shifts: instead of holding the whole task in your head, you steer the agent slice by slice, correct course on real feedback, and stop it from over-building.
Further reading
- Context Rot: How Increasing Input Tokens Impacts LLM Performance — Chroma's 2025 report; the empirical basis for the "smart zone" — accuracy degrades as context fills, across 18 models.
- Effective context engineering for AI agents — Anthropic on treating the context window as a finite budget: just-in-time retrieval, compaction, note-taking.
- Building effective agents — Anthropic's foundational guide to agent patterns and keeping each unit of work small and well-scoped.
- 12-Factor Agents — HumanLayer's production-agent principles: own the context window, prefer small focused agents.
Next: how to design the engineering environment so the slices land in a codebase that helps the agent — see Software Quality in the AI Era.
Background reading: Context window limits.
Edit this page on GitHub